Doppelgänger
Eina interactiva de detecció de clons de codi per identificar i eliminar codi Java duplicat.
2 min de lectura
Què és?
Doppelgänger és una aplicació interactiva que vaig crear amb el meu company de la universitat per identificar i ajudar a eliminar codi duplicat en aplicacions Java. Combina l’anàlisi AST (Arbre de Sintaxi Abstracta) del backend amb eines d’exploració visual per fer la detecció de clons de codi completa i útil.
L’eina analitza tant projectes locals com els allotjats en repositoris Git públics, i proporciona una interfície interactiva per explorar els clons detectats i treballar en la seva refactorització.
GitHub: https://github.com/loehnertz/Doppelgaenger
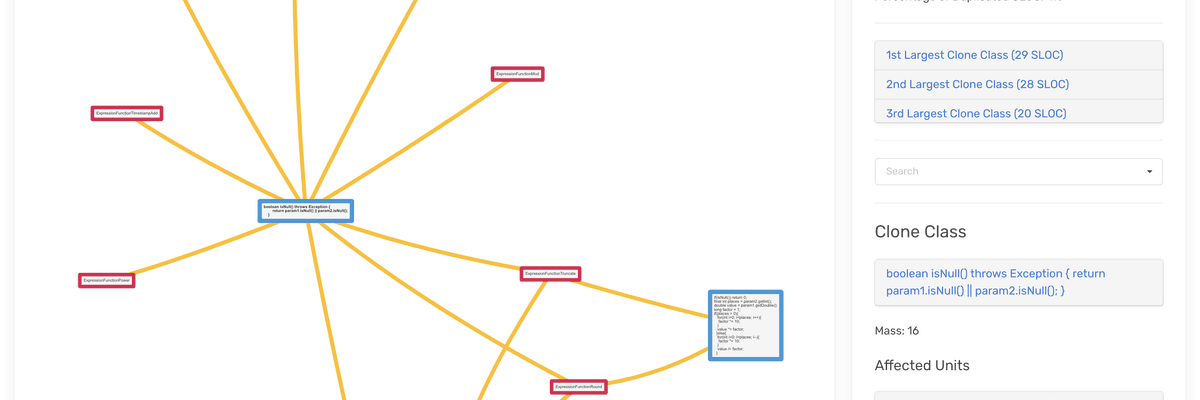
Tipus de detecció de clons
Doppelgänger suporta tres nivells de detecció de clons de codi:
Tipus u: Còpies exactes: Codi idèntic, ignorant només els espais en blanc i els comentaris. Els clons de “literalment he copiat i enganxat”.
Tipus dos: Similituds sintàctiques: Codi estructuralment similar amb variacions d’identificadors (com noms de variables diferents). Els clons de “he copiat i enganxat i he canviat el nom d’algunes coses”.
Tipus tres: Còpies modificades: Còpies de codi amb sentències modificades, afegides o eliminades. Els clons de “he copiat i enganxat i he canviat unes quantes línies”.
Pots configurar els llindars de similitud per equilibrar la precisió amb la velocitat, cosa que és important per a codis font grans on no vols esperar molt.
Com funciona
El backend utilitza l’anàlisi AST i el hashing per identificar clons de codi. Això és més fiable que la comparació simple de text perquè entén l’estructura del codi en lloc de comparar cadenes de text.
El frontend deixa explorar visualment els clons detectats – veure on són, com de similars són i quins tindrien el major impacte si es refactoritzessin.
Funcionalitats principals:
- Detectar codi font duplicat en projectes Java
- Analitzar projectes locals o repositoris Git públics
- Interfície de visualització avançada per explorar clons
- Flux de treball de refactorització interactiu
- Sensibilitat de detecció configurable
Stack tecnològic
Backend:
- Kotlin utilitzant el framework web Ktor
- Anàlisi AST (amb JavaParser) i hashing per a la identificació de clons
- Algorismes de similitud configurables
Frontend:
- Vue.js per a la capa de visualització interactiva
- Exploració en temps real dels clons detectats en vista de graf (amb vis.js)